I got some time to spend with Harper, a “free English grammar checker designed to be just right,” which can be integrated into Emacs.
Before I proceed, I want to note that while the description on the website from the creator states, “you can think of it as an open-source alternative to Grammarly,” I find this to be misleading. At least on Emacs on my Mac, Harper does not compare to what I get from my premium account on Grammarly1.
Still, if you’re looking for something free, open source, private, and fast, you should check out Harper.
To get Harper to work on a Mac, you want to install it from Homebrew, as the documentations show: brew install harper. Then for Emacs, Harper uses harper-ls, which is the Language Server Protocol server (LSP) for Harper. This is something that tripped me earlier: on Emacs, you do not interact with Harper directly, but with Emacs' built-in client for LSPs, Eglot, instead. Confused? I sure was. The part to remember is that we’re going to run M-x Eglot commands when we interact with Harper on Emacs.
A diagram would look something like this: Emacs > Eglot (LSP Client) > harper-ls (LSP Server) > Harper.
To configure Eglot to recognize and run with Harper’s LSP server, harper-ls, we can add the basic configuration to our Emacs init as described in Harper’s documentation, with a minor adjustment:
(with-eval-after-load 'eglot
(add-to-list 'eglot-server-programs
'(org-mode . ("harper-ls" "--stdio"))))
I’ve added the org-mode part instead of text-mode as described originally because I want Harper to work in org-mode. The credit for this goes to Jakub, who wrote about this in his blog and was also kind enough to email me directly and explain things even further when I was confused; so thanks Jakub! You’re alright in my book.
Jakub is from Australia, so he included a dialect option for Australian and a hook to launch eglot when org-mode is loaded, so that he wouldn’t need to launch it manually. Check his config in the link above with his explanations.
I changed my config’s dialect to American, as an option described in the documentation. After some time with Harper, I also decided to remove the org-mode hook because Harper will happily mark everything that looks like a mistake in org-mode buffers. This includes the agenda, checklists, code segments, etc.2. I also prefer to separate my editing from my writing, as I find these green zigzags distracting.
When I launch Harper in org-mode with Eglot, it looks like this:
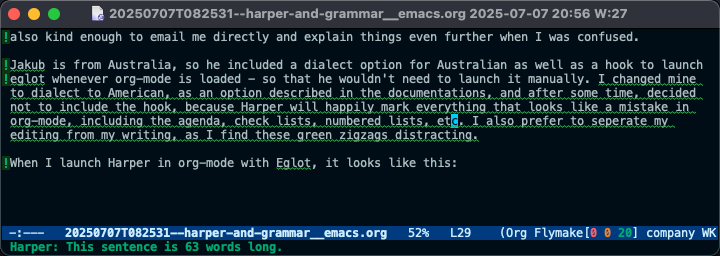
As you can see in the picture, I ran Harper on the draft of this post. It delimits every line with an issue with an exclamation point, then highlights the error with a green zigzag. When you hover over the grammatical error with the point (or the mouse cursor), Harper displays the error in the mini-buffer. In the case above, it lets me know I have a sentence that is too long.
You can correct mistakes directly with Harper by utilizing the correct Eglot commands (remember that you have to “talk” to Eglot to work with Harper). For example, you can use its Code Actions with eglot-code-actions, which will display a menu of available fixes to replace your text with. I’m quickly learning I should probably get a shortcut for this because I’m going to use this plenty. There are other aspects of Harper I’m still learning about; it comes with additional tweaks and configurations, including user dictionaries.
All in all, Harper does a decent job of catching most grammatical errors and spelling mistakes. However, I still find that I need to pass the text through Grammarly to catch some errors. For example, in this very post, the line where I wrote “It delimits every line with an issue…” was “It delimiters every line…” and Harper was okay with it. Harper also seems to miss my plural confusions, for example, “as an option described in the documentations,” is fine with Harper, but it should be “as an option described in the documentation.” Then there’s where, in my opinion, Grammarly shines next to other LLMs: style suggestions. I can ask Grammarly to make a part of the text shorter, more professional, more friendly, etc., and it will do so on the spot. Chat GPT and the like can do the same thing, but you have to do several copy-pastes to get to the same result, and even then, I find it’s not quite as polished. It’s also helpful to always have these versions in front of you so you can choose the style you want. Grammarly also highlights the errors it finds in different colors: definite issues will be in red, while suggestions for style will be in blue.
Many people don’t need this level of a “grammar nanny,” and I totally understand what Harper’s developers mean when they say Grammarly is overbearing. Add to that the fact that Grammarly sends all your private Emacs notes to the Grammarly servers, where they can do whatever they want with them, complete with the premium cost and… yeah, I totally get it. Meanwhile, Harper does most of the works, and fast, especially when compared to languageTool, which also requires you to install Java and deal with its weird updates. Oh, and those of you who use Obsidian: Harper has an official plugin, which I suspect works even better than what I wrote about here.
Give it a try, and if you’d like, let me know what you think. Meanwhile, I will see if I can make it my go-to grammar tool on my Linux Desktop.
Footnotes
1 : I get Grammarly through work. If that weren’t the case, I’m not so sure I’d rush to pay for it myself, which comes close to $30 a month.
2 : The reason Harper doesn’t know to ignore the org-mode syntax option for code (words between ~ ~) or other special characters is because org-mode is not yet officially supported. When this happens, I guess these issues will go away and I will try to launch Harper with a hook for org-mode again.






