Sacha Chua: Playing around with org-db-v3 and consult: vector search of my blog post Org files, with previews
I tend to use different words even when I'm writing about the same ideas.
When I use traditional search tools like grep, it can be hard to look up old blog posts or sketches if I can't think of the exact words I used.
When I write a blog post, I want to automatically remind myself of possibly relevant notes without requiring words to exactly match what I'm looking for.
Demo
Here's a super quick demo of what I've been hacking together so far, doing vector search on some of my blog posts using the .org files I indexed with org-db-v3:
Play by play:
- 0:00:00 Use
M-x my-blog-similar-linkto look for "forgetting things", flip through results, and use RET to select one. - 0:00:25 Select "convert the text into a link" and use
M-x my-blog-similar-linkto change it into a link. - 0:00:44 I can call it with
C-u M-x my-blog-similar-linkand it will do the vector search using all of the post's text. This is pretty long, so I don't show it in the prompt. - 0:00:56 I can use Embark to select and insert multiple links.
C-SPCselects them from the completion buffer, andC-. Aacts on all of them. - 0:01:17 I can also use Embark's
C-. S(embark-collect) to keep a snapshot that I can act on, and I can useRETin that buffer to insert the links.
Background
A few weeks ago, John Kitchin demonstrated a vector search server
in his video Emacs RAG with LibSQL - Enabling
semantic search of org-mode headings with Claude
Code - YouTube. I checked out
jkitchin/emacs-rag-libsql and got the server
running. My system's a little slow (no GPU), so
(setq emacs-rag-http-timeout nil) was helpful.
It feels like a lighter-weight version of Khoj
(which also supports Org Mode
files) and maybe more focused on Org than jwiegley/rag-client. At the moment,
I'm more interested in embeddings and
vector/hybrid search than generating summaries or
using a conversational interface, so something
simple is fine. I just want a list of
possibly-related items that I can re-read myself.
Of course, while these notes were languishing in
my draft file, John Kitchin had already moved on
to something else.
He posted Fulltext, semantic text and image search
in Emacs - YouTube, linking to a new vibe-coded
project called org-db-v3 that promises to offer
semantic, full-text, image, and headline search.
The interface is ever so slightly different: POST
instead of GET, a different data structure for
results.
Fortunately, it was easy enough to adapt my code.
I just needed a small adapter function to make the
output of org-db-v3 look like the output from
emacs-rag-search.
(use-package org-db-v3
:load-path "~/vendor/org-db-v3/elisp"
:init
(setq org-db-v3-auto-enable nil))
(defun my-org-db-v3-to-emacs-rag-search (query &optional limit filename-pattern)
"Search org-db-v3 and transform the data to look like emacs-rag-search's output."
(org-db-v3-ensure-server)
(setq limit (or limit 100))
(mapcar (lambda (o)
`((source_path . ,(assoc-default 'filename o))
(line_number . ,(assoc-default 'begin_line o))))
(assoc-default 'results
(plz 'post (concat (org-db-v3-server-url) "/api/search/semantic")
:headers '(("Content-Type" . "application/json"))
:body (json-encode `((query . ,query)
(limit . ,limit)
(filename_pattern . ,filename-pattern)))
:as #'json-read))))
I'm assuming that org-db-v3 is what John's going
to focus on instead of emacs-rag-search (for
now, at least). I'll focus on that for the rest of
this post, although I'll include some of the
emacs-rag-search stuff just in case.
Indexing my Org files
Both emacs-rag and org-db-v3 index Org files by
submitting them to a local web server. Here are the key files I want to index:
- organizer.org: my personal projects and reference notes
- reading.org: snippets from books and webpages
- resources.org: bookmarks and frequently-linked sites
- posts.org: draft posts
(dolist (file '("~/sync/orgzly/organizer.org"
"~/sync/orgzly/posts.org"
"~/sync/orgzly/reading.org"
"~/sync/orgzly/resources.org"))
(org-db-v3-index-file-async file))
(emacs-rag uses emacs-rag-index-file instead.)
Indexing blog posts via exported Org files
Then I figured I'd index my recent blog posts,
except for the ones that are mostly lists of
links, like Emacs News or my weekly/monthly/yearly
reviews. I write my posts in Org Mode before
exporting them with ox-11ty and converting them
with the 11ty static site generator. I'd
previously written some code to automatically
export a copy of my Org draft in case people
wanted to look at the source of a blog post, or in
case I wanted to tweak the post in the future.
(Handy for things like Org Babel.) This was
generally exported as an index.org file in the
post's directory. I can think of a few uses for a
list of these files, so I'll make a function for
it.
(defun my-blog-org-files-except-reviews (after-date)
"Return a list of recent .org files except for Emacs News and weekly/monthly/yearly reviews.
AFTER-DATE is in the form yyyy, yyyy-mm, or yyyy-mm-dd."
(setq after-date (or after-date "2020"))
(let ((after-month (substring after-date 0 7))
(posts (my-blog-posts)))
(seq-keep
(lambda (filename)
(when (not (string-match "[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-emacs-news" filename))
(when (string-match "/blog/\\([0-9]+\\)/\\([0-9]+\\)/" filename)
(let ((month (match-string 2 filename))
(year (match-string 1 filename)))
(unless (string> after-month
(concat year "-" month))
(let ((info (my-blog-post-info-for-url (replace-regexp-in-string "~/proj/static-blog\\|index\\.org$\\|\\.org$" "" filename) posts)))
(let-alist info
(when (and
info
(string> .date after-date)
(not (seq-intersection .categories
'("emacs-news" "weekly" "monthly" "yearly")
'string=)))
filename))))))))
(sort
(directory-files-recursively "~/proj/static-blog/blog" "\\.org$")
:lessp #'string<
:reverse t))))
This is in the Listing exported Org posts section of my config. I have a my-blog-post-info-for-url function that helps me look up the categories. I get the data out of the JSON that has all of my blog posts in it.
Then it's easy to index those files:
(mapc #'org-db-v3-index-file-async (my-blog-org-files-except-reviews))
Searching my blog posts
Now that my files are indexed, I want to be able to turn up things that might be related to whatever I'm currently writing about. This might help me build up thoughts better, especially if a long time has passed in between posts.
org-db-v3-semantic-search-ivy didn't quite work for me out of the box, but I'd written an Consult-based interface for emacs-rag-search-vector that was easy to adapt. This is how I put it together.
First I started by looking at emacs-rag-search-vector. That shows the full chunks, which feels a little unwieldy.
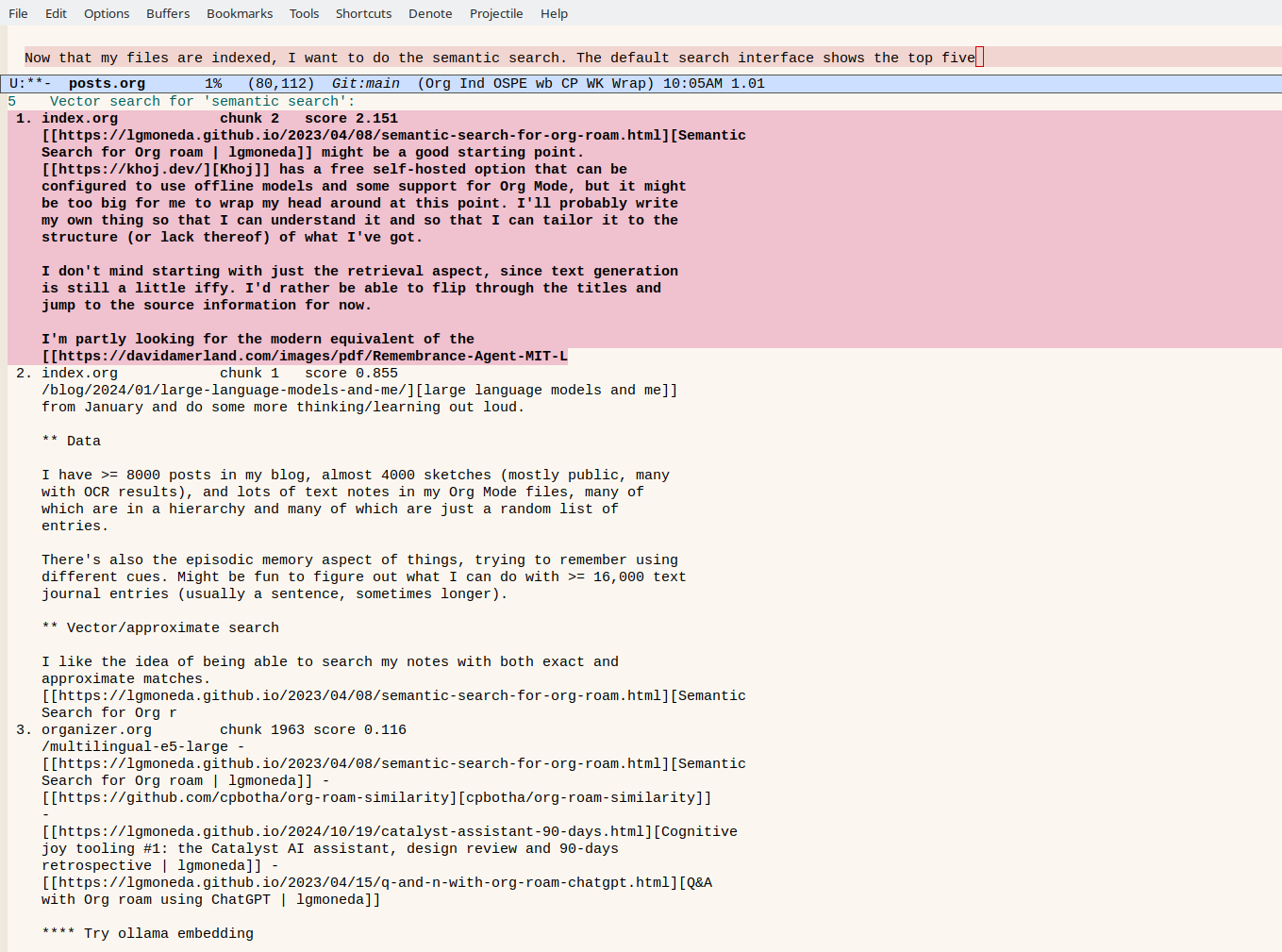
Instead, I wanted to see the years and titles of the blog posts as a quick summary, with the ability to page through them for a quick preview. consult.el lets me define a custom completion command with that behavior. Here's the code:
(defun my-blog-similar-link (link)
"Vector-search blog posts using `emacs-rag-search' and insert a link.
If called with \\[universal-argument\], use the current post's text.
If a region is selected, use that as the default QUERY.
HIDE-INITIAL means hide the initial query, which is handy if the query is very long."
(interactive (list
(if embark--command
(read-string "Link: ")
(my-blog-similar
(cond
(current-prefix-arg (my-11ty-post-text))
((region-active-p)
(buffer-substring (region-beginning)
(region-end))))
current-prefix-arg))))
(my-embark-blog-insert-link link))
(defun my-embark-blog--inject-target-url (&rest args)
"Replace the completion text with the URL."
(delete-minibuffer-contents)
(insert (my-blog-url (get-text-property 0 'consult--candidate (plist-get args :target)))))
(with-eval-after-load 'embark
(add-to-list 'embark-target-injection-hooks '(my-blog-similar-link my-embark-blog--inject-target-url)))
(defun my-blog-similar (&optional query hide-initial)
"Vector-search blog posts using `emacs-rag-search' and present results via Consult.
If called with \\[universal-argument\], use the current post's text.
If a region is selected, use that as the default QUERY.
HIDE-INITIAL means hide the initial query, which is handy if the query is very long."
(interactive (list (cond
(current-prefix-arg (my-11ty-post-text))
((region-active-p)
(buffer-substring (region-beginning)
(region-end))))
current-prefix-arg))
(consult--read
(if hide-initial
(my-org-db-v3-blog-post--collection query)
(consult--dynamic-collection
#'my-org-db-v3-blog-post--collection
:min-input 3 :debounce 1))
:lookup #'consult--lookup-cdr
:prompt "Search blog posts (approx): "
:category 'my-blog
:sort nil
:require-match t
:state (my-blog-post--state)
:initial (unless hide-initial query)))
(defvar my-blog-semantic-search-source 'org-db-v3)
(defun my-org-db-v3-blog-post--collection (input)
"Perform the RAG search and format the results for Consult.
Returns a list of cons cells (DISPLAY-STRING . PLIST)."
(let ((posts (my-blog-posts)))
(mapcar (lambda (o)
(my-blog-format-for-completion
(append o
(my-blog-post-info-for-url (alist-get 'source_path o)
posts))))
(seq-uniq
(my-org-db-v3-to-emacs-rag-search input 100 "%static-blog%")
(lambda (a b) (string= (alist-get 'source_path a)
(alist-get 'source_path b)))))))
It uses some functions I defined in other parts of my config:
- Making it easier to add a category to a blog post
my-embark-blog-insert-linkmy-blog-format-for-completion
- Tooting a link to the current post
my-11ty-post-text
When I explored emacs-rag-search, I also tried
hybrid search (vector + full text). At first, I
got "database disk image is malformed". I fixed
this by dumping the SQLite3 database. Using hybrid
search, I tended to get less-relevant results
based on the repetition of common words, though,
so that might be something for future exploration.
Anyway, my-emacs-rag-search and
my-emacs-rag-search-hybrid are in the
emacs-rag-search part of my config just in case.
Along the way, I contributed some notes to
consult.el's README.org so that it'll be easier to
figure this stuff out in the future. In
particular, it took me a while to figure out how
to use :lookup #'consult--lookup-cdr to get
richer information after selecting a completion
candidate, and also how to use
consult--dynamic-collection to work with slower
dynamic sources.
Quick thoughts and next steps
It is kinda nice being able to look up posts without using the exact words.
Now I can display a list of blog posts that are somewhat similar to what I'm currently working on. It should be pretty straightforward to filter the list to show only posts I haven't linked to yet.
I can probably get this to index the text versions of my sketches, too.
It might also be interesting to have a multi-source Consult command that starts off with fast sources (exact title or headline match) and then adds the slower sources (Google web search, semantic blog post search via org-db-v3) as the results become available.
I'll save that for another post, though!
You can comment on Mastodon or e-mail me at sacha@sachachua.com.
-1:-- Playing around with org-db-v3 and consult: vector search of my blog post Org files, with previews (Post Sacha Chua)--L0--C0--2025-10-29T00:32:24.000Z

{kind=link}